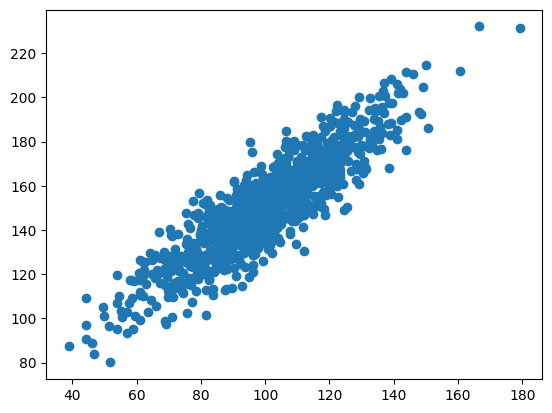
# calculate the Pearson's correlation between two variablesfrom numpy import meanfrom numpy import stdfrom numpy import covfrom numpy.random import randnfrom numpy.random import seedfrom matplotlib import pyplot as pltimport seaborn as snsfrom scipy.stats import pearsonr# seed random number generatorseed(1)# prepare datadata1 =20* randn(1000) +100# generating a 1000 reandom numbers with mean of 0 +100 and sd 20data2 = data1 + (10* randn(1000) +50) # data 1 no plus second random number with mean 50 and sd 10 - result is that data is approx 50 more than data 1# calculate covariance matrixcovariance = cov(data1, data2)# calculate Pearson's correlationcorr, _ = pearsonr(data1, data2)# plotplt.scatter(data1, data2)plt.show()# summarizeprint('data1: mean=%.3f stdv=%.3f'% (mean(data1), std(data1)))print('data2: mean=%.3f stdv=%.3f'% (mean(data2), std(data2)))print('Covariance: %.3f'% covariance[0][1])print('Pearsons correlation: %.3f'% corr)
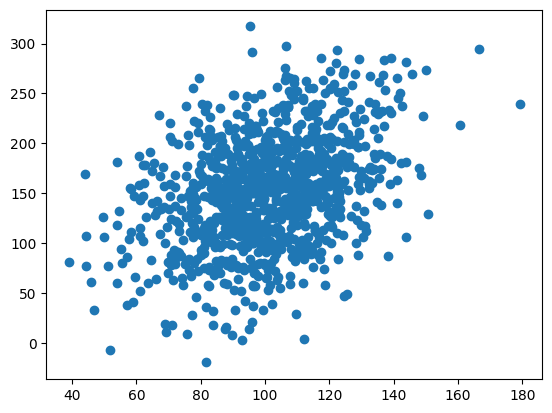
# changing the SDfrom scipy.stats import pearsonr# seed random number generatorseed(1)# prepare datadata1 =20* randn(1000) +100# generating a 1000 reandom numbers with mean of 0 +100 and sd 20data2 = data1 + (50* randn(1000) +50) # data 1 no plus second random number with mean 50 and sd 10 - result is that data is approx 50 more than data 1# calculate covariance matrixcovariance = cov(data1, data2)# calculate Pearson's correlationcorr, _ = pearsonr(data1, data2)# plotplt.scatter(data1, data2)plt.show()# summarizeprint('data1: mean=%.3f stdv=%.3f'% (mean(data1), std(data1)))print('data2: mean=%.3f stdv=%.3f'% (mean(data2), std(data2)))print('Covariance: %.3f'% covariance[0][1])print('Pearsons correlation: %.3f'% corr)
Increasing the SD made the data spread wider in the x axis for data1 variable and wider in the y axis for data2 variable; this is as expected as the variance and sd will increase. If the sd increases in both data1 and data2 together then the correlation decreases (again, as expected as the data points can vary more around the mean and are therefore less tightly constrained). If SD for data1 increases only then correlation becomes stronger, however if sd increases for y axis (data2) then the correlation is reduced (because this number is generated from data 1)
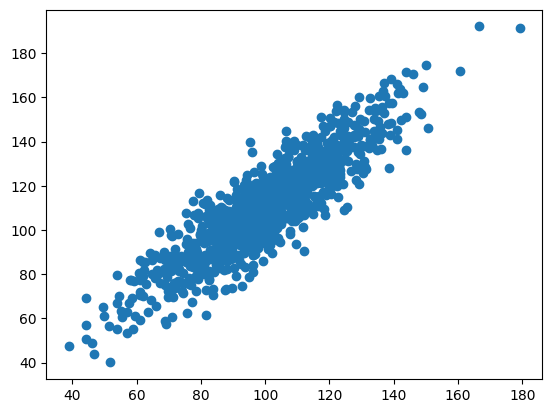
# change meanfrom scipy.stats import pearsonr# seed random number generatorseed(1)# prepare datadata1 =20* randn(1000) +100# generating a 1000 reandom numbers with mean of 0 +100 and sd 20data2 = data1 + (10* randn(1000) +10) # data 1 no plus second random number with mean 50 and sd 10 - result is that data is approx 50 more than data 1# calculate covariance matrixcovariance = cov(data1, data2)# calculate Pearson's correlationcorr, _ = pearsonr(data1, data2)# plotplt.scatter(data1, data2)plt.show()# summarizeprint('data1: mean=%.3f stdv=%.3f'% (mean(data1), std(data1)))print('data2: mean=%.3f stdv=%.3f'% (mean(data2), std(data2)))print('Covariance: %.3f'% covariance[0][1])print('Pearsons correlation: %.3f'% corr)
changing the mean shifts the dataset on the x or y axis, no effect on correlation, this is as expected as changing the mean value just shifts the data set around a different mean point.
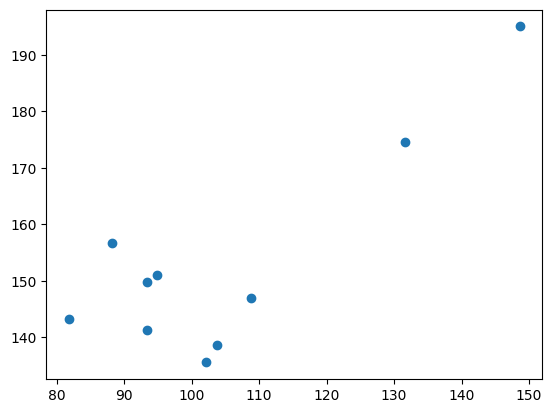
# change number of data pointsfrom scipy.stats import pearsonr# seed random number generatorseed(5)# prepare datadata1 =20* randn(10) +100# generating a 1000 reandom numbers with mean of 0 +100 and sd 20data2 = data1 + (10* randn(10) +50) # data 1 no plus second random number with mean 50 and sd 10 - result is that data is approx 50 more than data 1# calculate covariance matrixcovariance = cov(data1, data2)# calculate Pearson's correlationcorr, _ = pearsonr(data1, data2)# plotplt.scatter(data1, data2)plt.show()# summarizeprint('data1: mean=%.3f stdv=%.3f'% (mean(data1), std(data1)))print('data2: mean=%.3f stdv=%.3f'% (mean(data2), std(data2)))print('Covariance: %.3f'% covariance[0][1])print('Pearsons correlation: %.3f'% corr)
Changing the number of data points can effect the data shape and correlation value depending on seed given - Q how many data points do you need to be confident in the correlation value given, i.e. with 10 points and seed = 1,correlation = 0.971; but when seed = 5 correlation is 0.823 and despite coreelation coefficent suggesting a strong positive correlation, the graph above is not very convicing.